Matrices for EVD and SVD from data mining applications
constructed by: Zheng Wang and Yunkai Zhou
These matrices are constructed from major datasets used in LSI
(latent semantics indexing) applications
as well as in several graph-kernel-based learning techniques. The basic info of the matrices are
listed in Table 1.
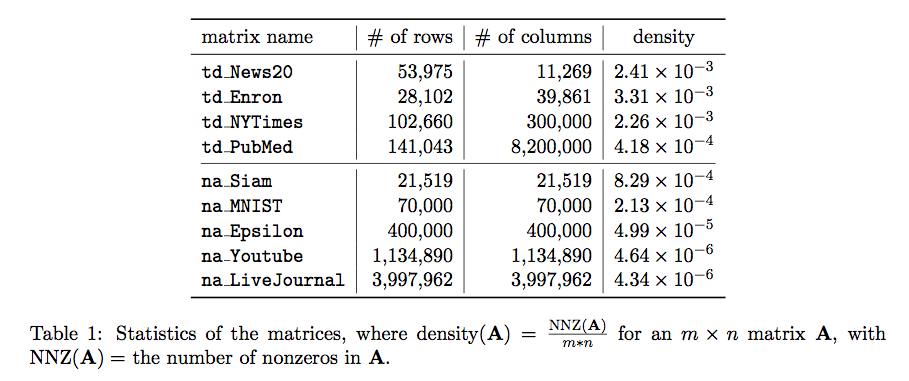 In the names of matrices, the 'td_' refers to term-document matrices, and the 'na_' refers to normalized
adjacency matrices.
In the names of matrices, the 'td_' refers to term-document matrices, and the 'na_' refers to normalized
adjacency matrices.
We use public domain datasets for the construction of these matrices.
For the term-document matrices, we use
the datasets Enron Emails [ UCI_data ], 20 Newsgroups [ news20 ], NYTimes News Articles [ UCI_data ], and PubMed Abstracts [ UCI_data], are bag-of-words files recording the number of occurrences of every word in every text. We construct the term-document matrices from these datasets using the
TF-IDF (term frequency - inverse document frequency) weighting.
For the normalized adjacency matrices,
we construct them from five datasets: SIAM_competition
[LIBSVM], MNIST [MNIST], epsilon [LIBSVM], Youtube_network [network], and LiveJournal_network [network].
We first convert the datasets
into unweighted 10-nearest-neighbor (10NN) graphs according to Euclidean distances
[spectral_transform_graph_kernel].
That is, two distinct vertexes are connected by an edge of weight 1
if either one of them is among the 10 nearest neighbors of the other,
measured in the Euclidean distance; otherwise they are not linked by an edge.
Once each dataset is represented as a graph, we can construct its adjacency matrix and then
apply the standard normalization to get the normalized adjacency matrix for this graph.
All the matrices are stored in the standard Matlab binary format (with the .mat extension).
They are compressed using gzip. The sparsity structures are drawn using the
cspy.m code from the
SuiteSparse package.
-
Normalized adjacency matrices
All the eigenvalues of these normalized adjacency matrices are located inside the [-1, 1] interval.
When the dimension of a normalized adjacency matrix becomes large, the eigenvalues become highly clustered,
thus making them very challenging to compute.
(If you are developing new eigen-algorithms, the first two matrices below should provide
two adequate tests.)
-
[ 10nn_youtube ]
We construct the matrix from the dataset Youtube_network, which
is transformed into an undirected graph that models an online social networks.
Youtube_network has 1,134,890 vertices with 2,987,624 edges.
The sparsity structure of the matrix is
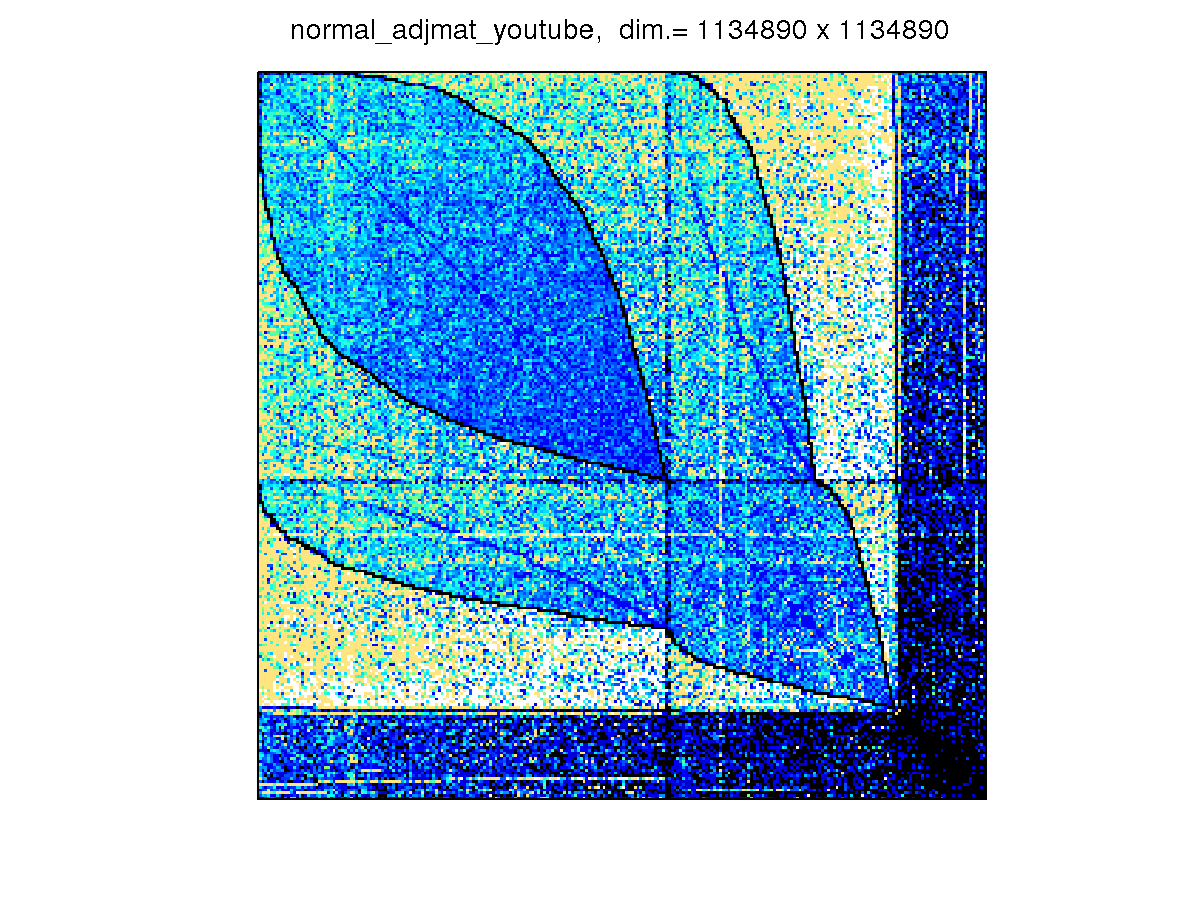
-
[ 10nn_live_journals ]
We construct the matrix from the dataset LiveJournal_network, which is also transformed into an undirected graph. It
has 3,997,962 vertices with 3,4681,189 edges.
The sparsity structure is
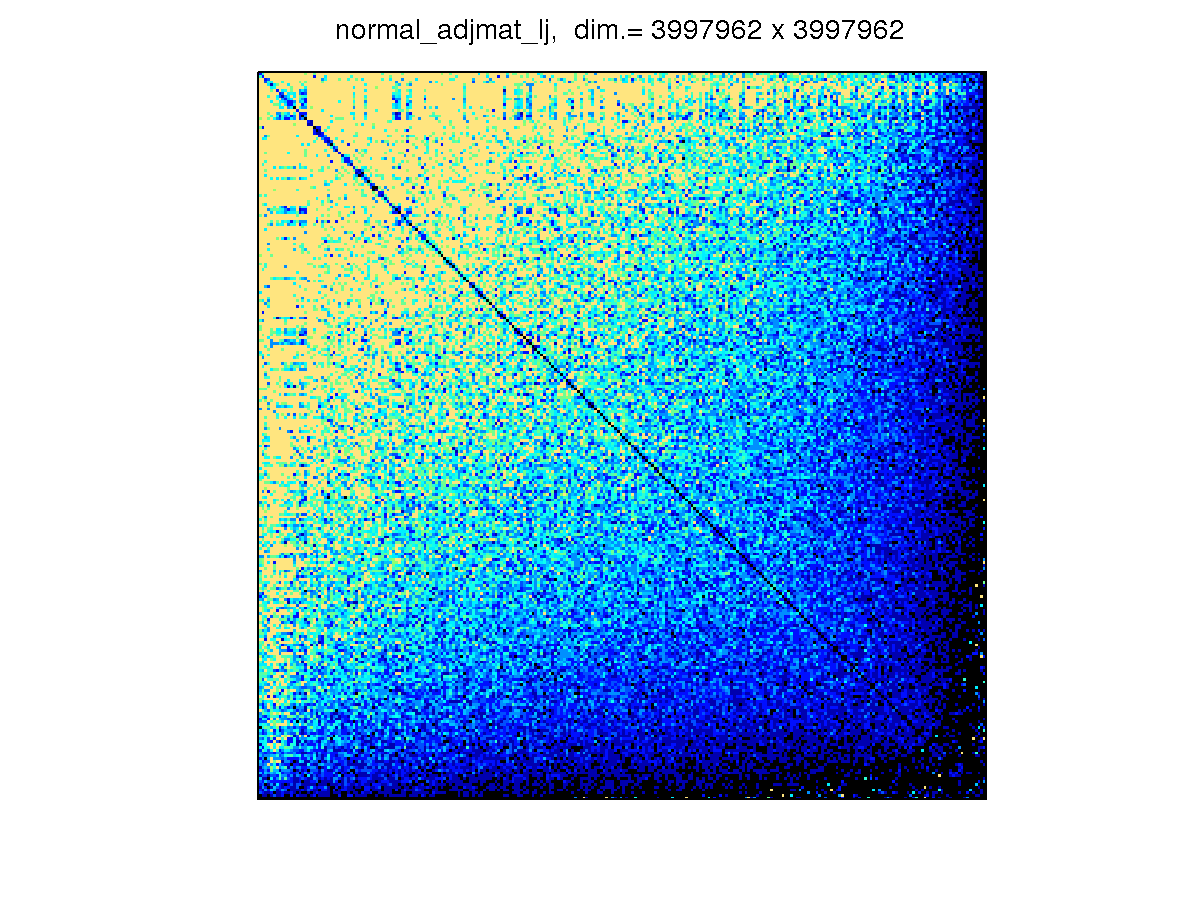
-
[ 10nn_siam ]
This matrix is constructed from a collection of texts for a SIAM competition on text classification. It contains 21,519 data points, each having 30,438 features. Each data point represents a text, and its features are binary term frequencies of the words in the text. All data points are then normalized to unit length.
The sparsity structure is

-
[ 10nn_mnist ]
We construct the normalized adjacency matrix from the dataset MNIST.
MNIST contains a collection of images of handwritten digits (integers from 0 to 9). It contains 70,000 data points, each having 784 features. Each data point represents an image of 28×28 pixels. This dataset is often used for testing pattern recognition methods such as learning algorithms for classification and clustering.
The sparsity structure is

-
[ 10nn_epsilon ]
We construct the normalized adjacency matrix from epsilon, which is an artificial dataset used in the
Pascal Large Scale Learning Challenge on classification. It contains 500,000 data points, each having 2,000 features.
The sparsity structure is
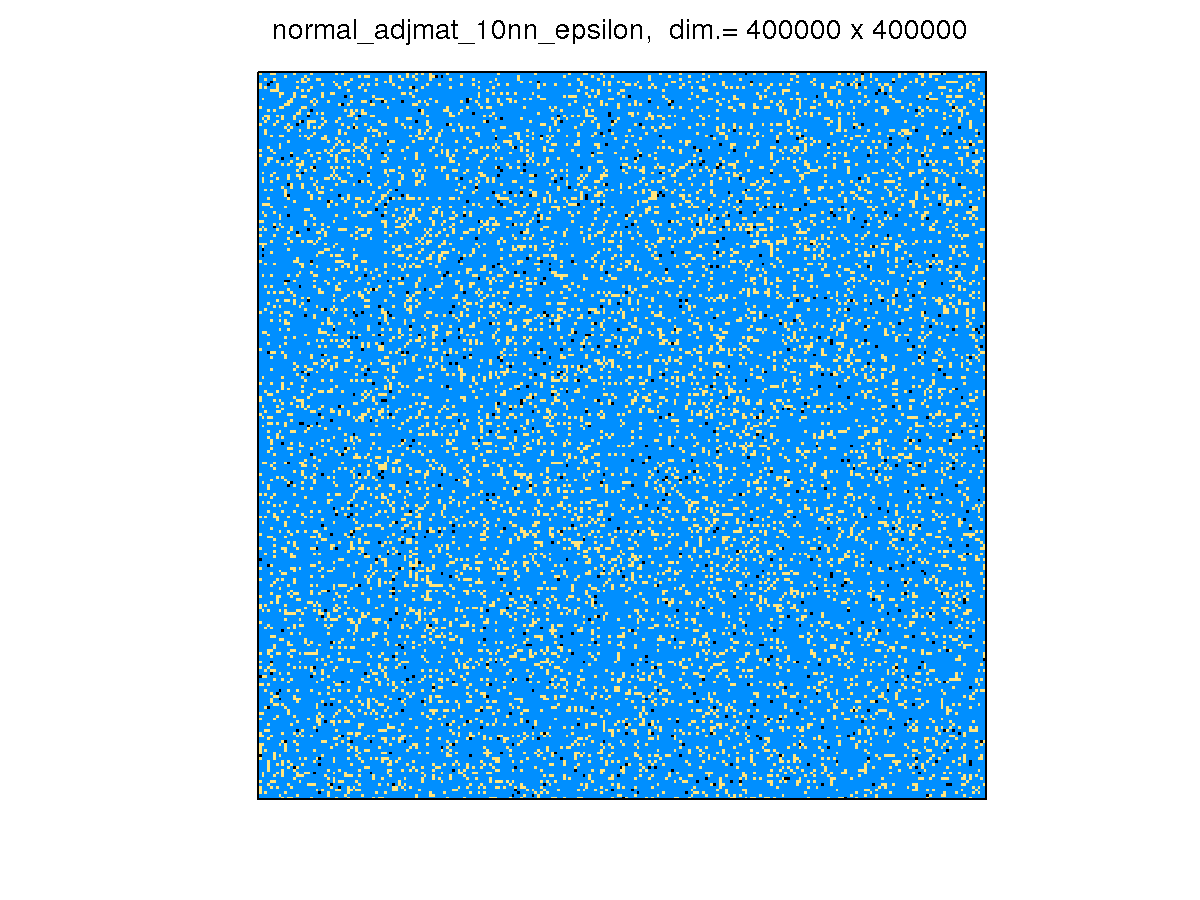
-
Term document (non-square) matrices for SVD calculations
-
[ tdmat_enron_emails ]
The sparsity structure is
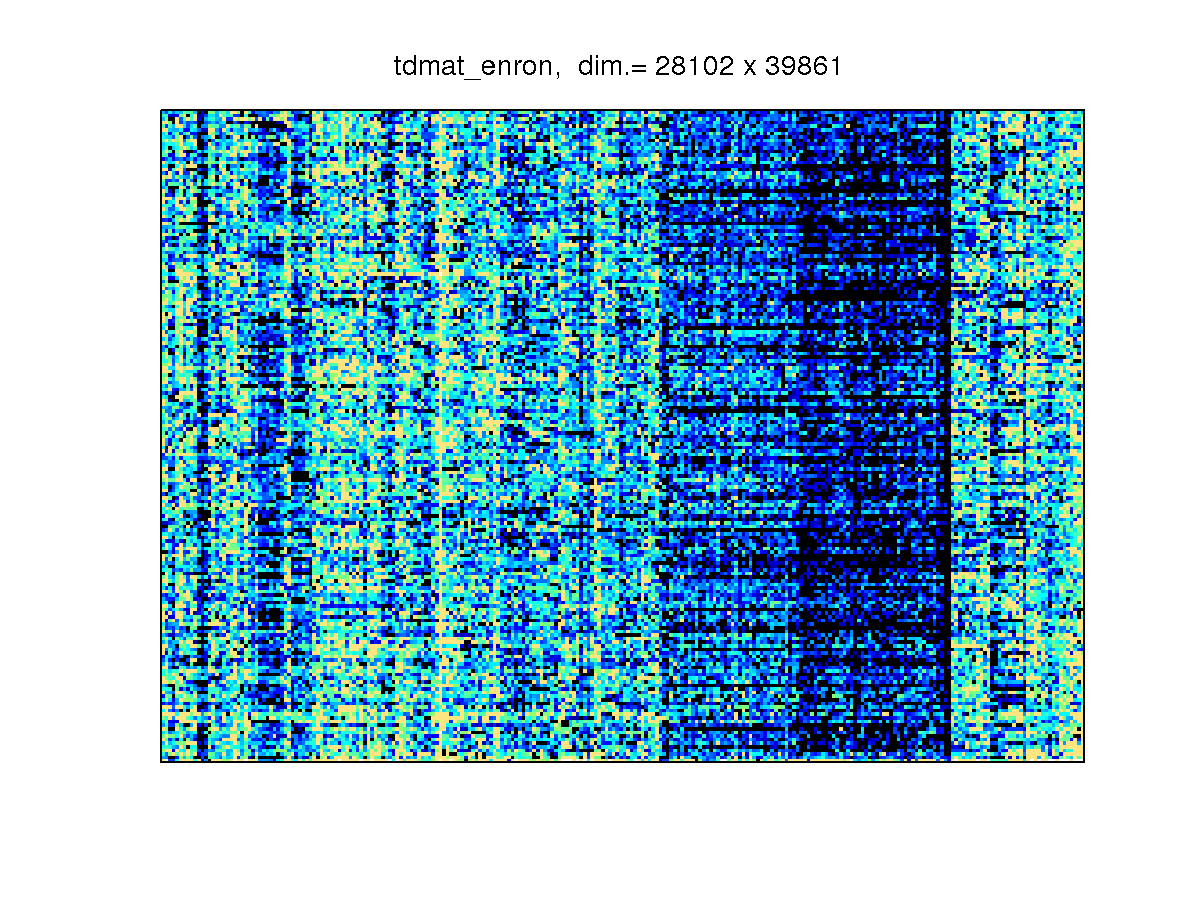
-
[ tdmat_20_newsgroups ]
The sparsity structure is
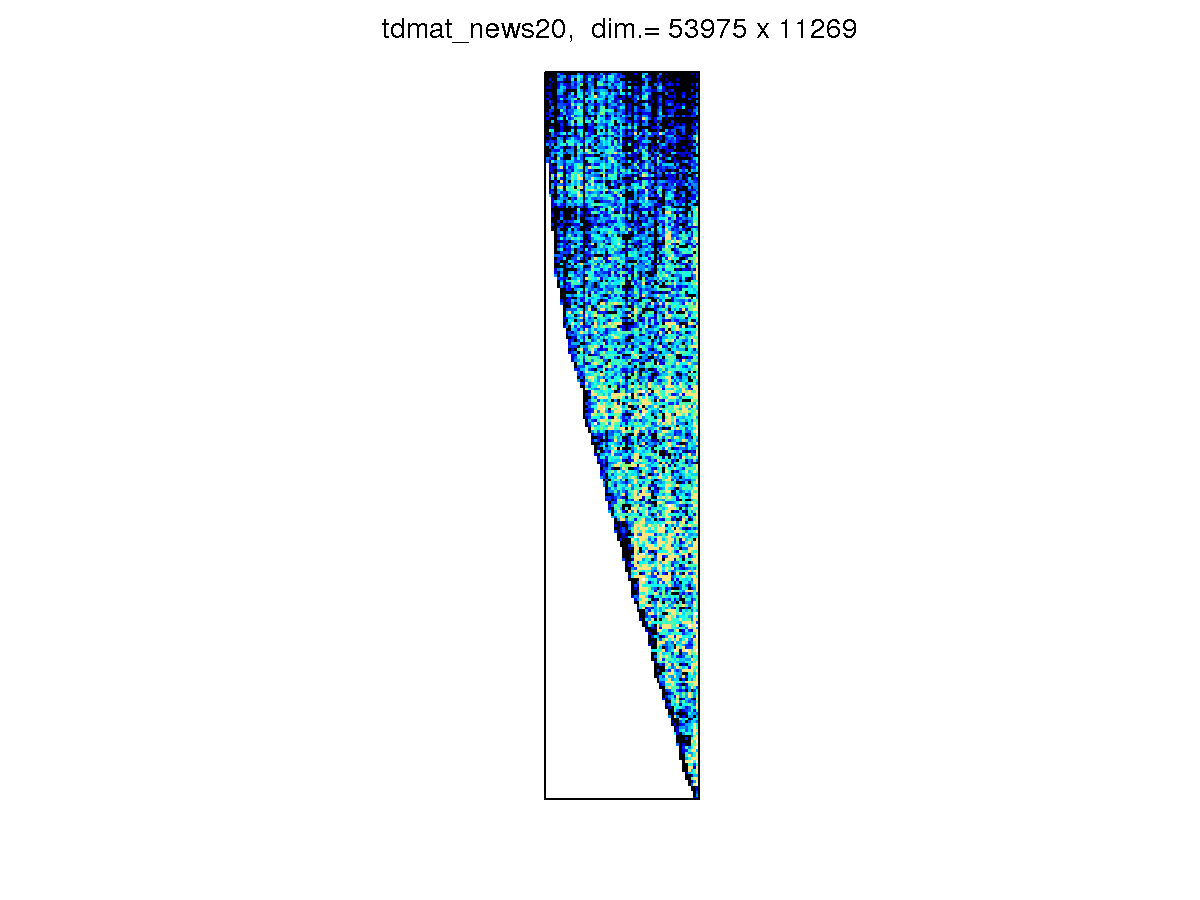
-
[ tdmat_nytimes_articles ]
The sparsity structure is
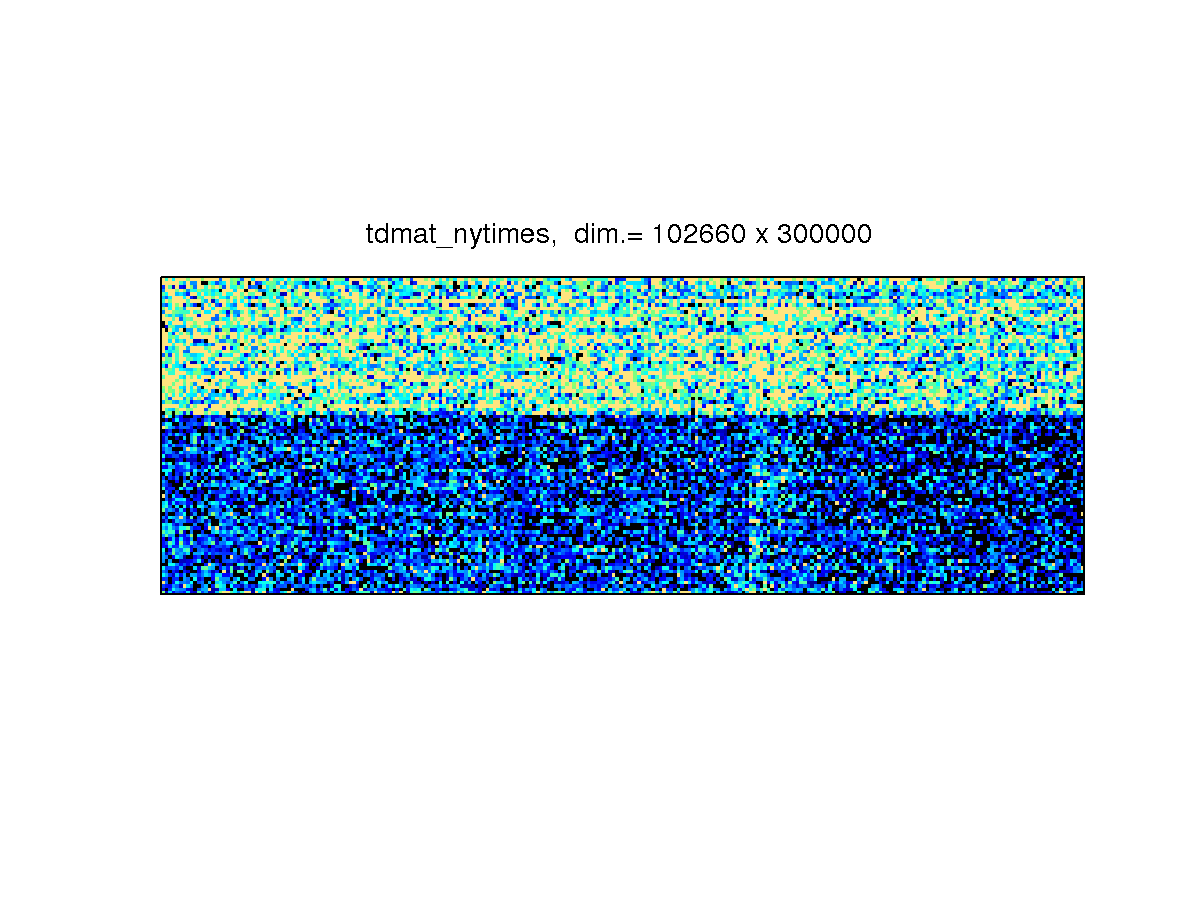
References
- [UCI_data]
- K. Bache and M. Lichman. UCI machine learning repository.
http://archive.ics.uci.edu/ml, 2013.
- [LIBSVM]
- R.-E. Fan and C.-J. Lin.
Libsvm data: Classification, regression, and multi-label.
http://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/.
- [MNIST]
-
Y. LeCun, C. Cortes, and C. J.C. Burges.
The mnist database of handwritten digits.
http://yann.lecun.com/exdb/mnist/.
- [network]
-
Jure Leskovec and Andrej Krevl.
SNAP Datasets: Stanford large network dataset collection.
http://snap.stanford.edu/data, 2014.
- [news20]
-
J. Rennie.
20 newsgroups.
http://qwone.com/~jason/20Newsgroups/, 2008.
- [spectral_transform_graph_kernel]
-
X. Zhu, J. Kandola, J. Lafferty, and Z. Ghahramani.
Graph kernels by spectral transforms.
In O. Chapelle, B. Scholkopf, and A. Zien, editors, Semi-Supervised Learning, pages 277–291. MIT Press, 2006.
back to ykz mainpage
Last modified:
Nov. 2015