Session 17: Introduction to Heterogeneous Programming Concepts
Motivation
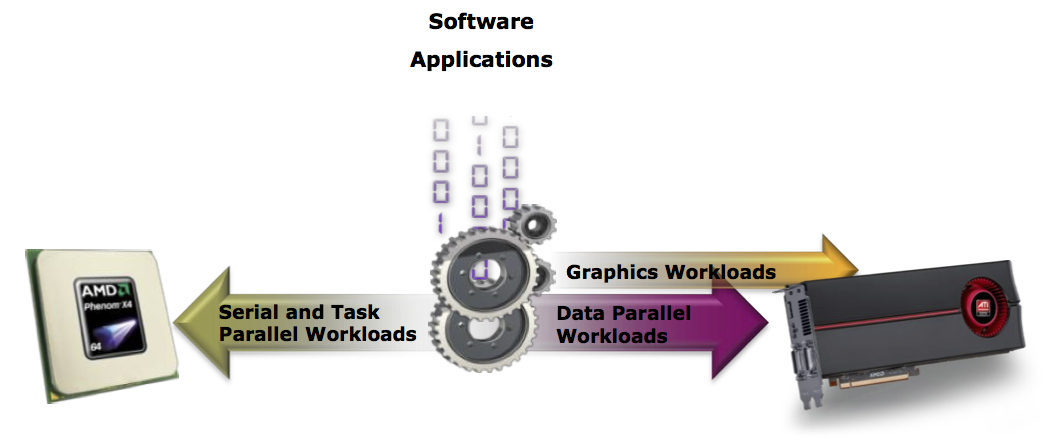
Heterogeneous computing is the use of hardware that is specialized to a particular task. This enables hardware based acceleration of programs for specific areas of their code. These devices are commonly referred to accelerators. Examples include cryptographic accelerators, field-programable gate arrays (FPGAs), digital signal processors (DSPs), and graphics processing units (GPUs).
The primary motivation for both the development of GPUs and then their use as general computational devices is speed. The operations generally need for graphics manipulation are being done constantly. Thus, by offloading them to a specialized device where these operations could be done in hardware greatly decreased the amount of time needed to perform the operations. Over time, the same is now true for classes of calculations other than relavent to graphics operations.
Graphics processing units (GPUs) have been heavily used in computing for some time. These devices were originally designed for the acceleration of the calculations needed to on-screen display graphics. Due to the nature of rasterized graphics data, operations done on the data could be done much faster if done in parallel. Thus, GPUs evolved to be highly parallel processors with graphics-specific operations done in hardware rather than software. The end result of the use of these processors is that graphics processing performance is significantly improved while simultaneously deceasing the computational burden on the central processing unit (CPU), thus freeing it for other tasks.
GPUs have increased in performance and complexity to the point where tasks beyond graphics-specific calculations could be performed on them leading to the advent of general-purpose graphics processing units (GPGPU).
General-purpose GPU computing or GPGPU computing is the use of a GPU (graphics processing unit) to do general purpose scientific and engineering computing. The model for GPU computing is to use a CPU and GPU together in a heterogeneous co-processing computing model. The sequential part of the application runs on the CPU and the computationally-intensive part is accelerated by the GPU. From the user’s perspective, the application just runs faster because it is using the high-performance of the GPU to boost performance.
The GPU has evolved over the years to have teraflops of floating point performance.
The success of GPGPUs in the past few years has been the ease of programming of the associated OpenCL and CUDA parallel programming models. In these programming models, the application developer modifies their application to take the compute-intensive kernels and map them to the GPU. The rest of the application remains on the CPU. Mapping a function to the GPU involves rewriting the function to expose the parallelism in the function and adding “C” keywords to move data to and from the GPU.
The Intel Phi accelerator has also been very successful as its cores are simplified x86 cores.


Modern GPGPU Computing and Associated Languages
- Potential for very high performance at low cost
- Architecture well suited for certain kinds of parallel applications (data parallel)
- Demonstrations of 30-100X speedup over CPU
- Some convergence between commodity and GPUs and their associated parallel programming models
- Programmer can express parallelism at a high level
- Correctness is not difficult to achieve
- Portable across platforms
- Performance gains over sequential easily achievable
Heterogeneous Architectures
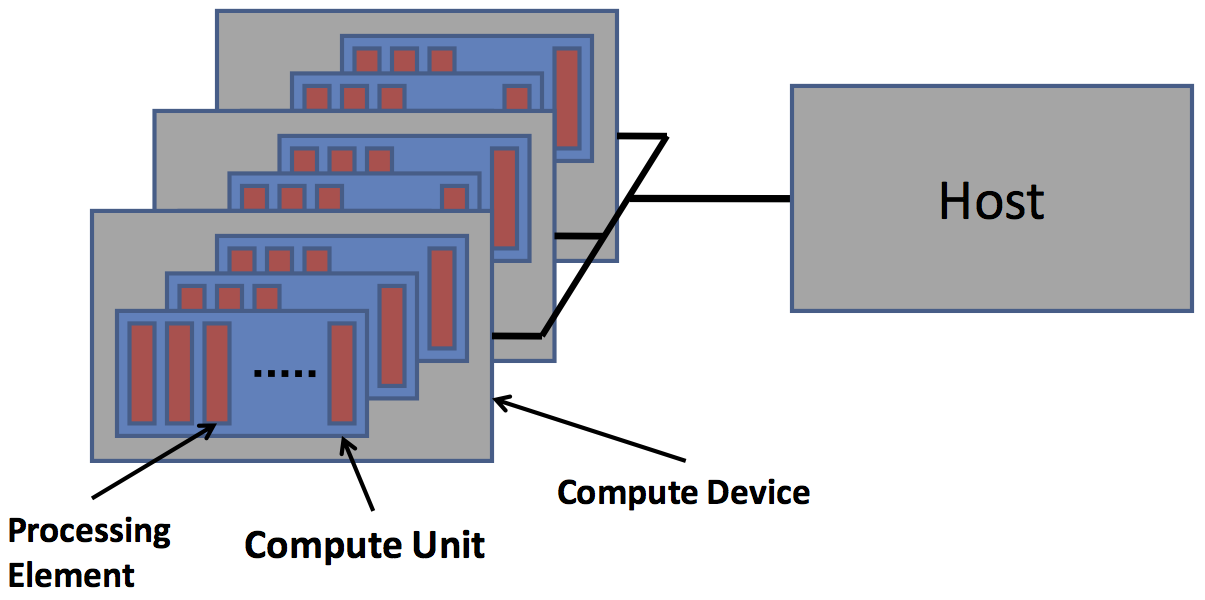
Accelerators (GPGPUs) are highly multithreaded coprocessors.
- The GPU is viewed as a compute device that:
- Is a coprocessor to the CPU or host
- Has its own DRAM (device memory)
- Runs many threads in parallel
- Data-parallel portions of an application are executed on the device as kernels which run in parallel on many threads
- Differences between GPU and CPU threads
- GPU threads are extremely lightweight
- Very little creation overhead
- GPU needs 1000s of threads for full efficiency
- Multi-core CPU needs only a few
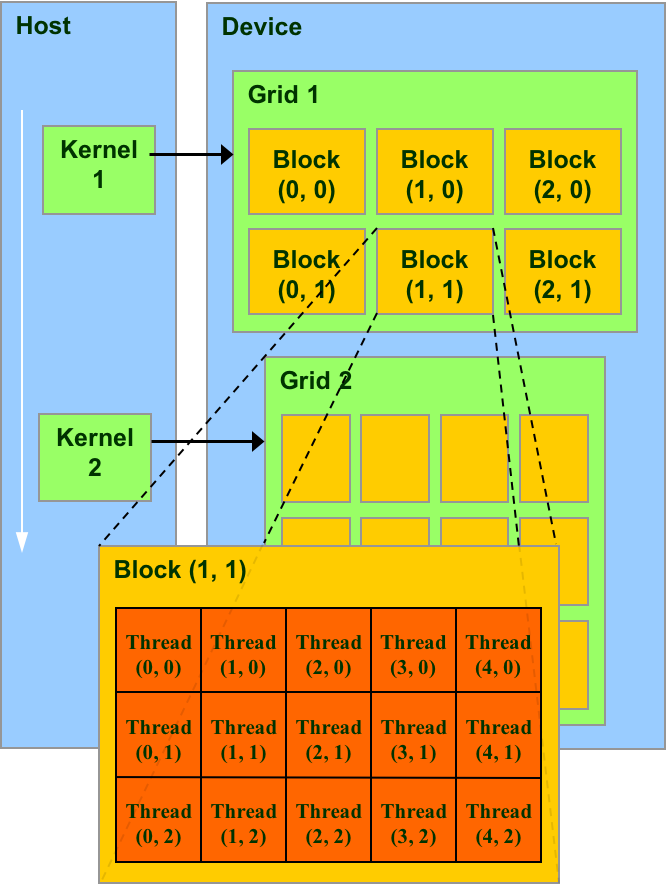
- A kernel is executed as a grid of thread blocks
- All threads share data memory space
- A thread block is a batch of threads that can cooperate with each other by:
- Synchronizing their execution
- For hazard-free shared memory accesses
- Efficiently sharing data through a low latency shared memory
- Two threads from two different blocks cannot cooperate
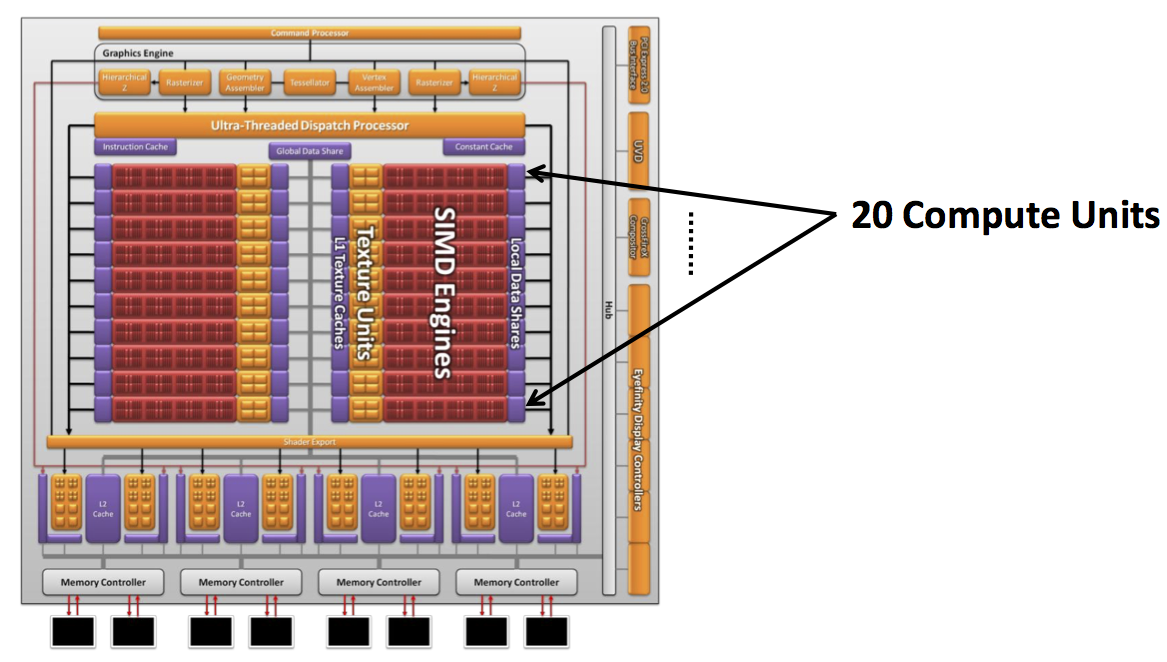
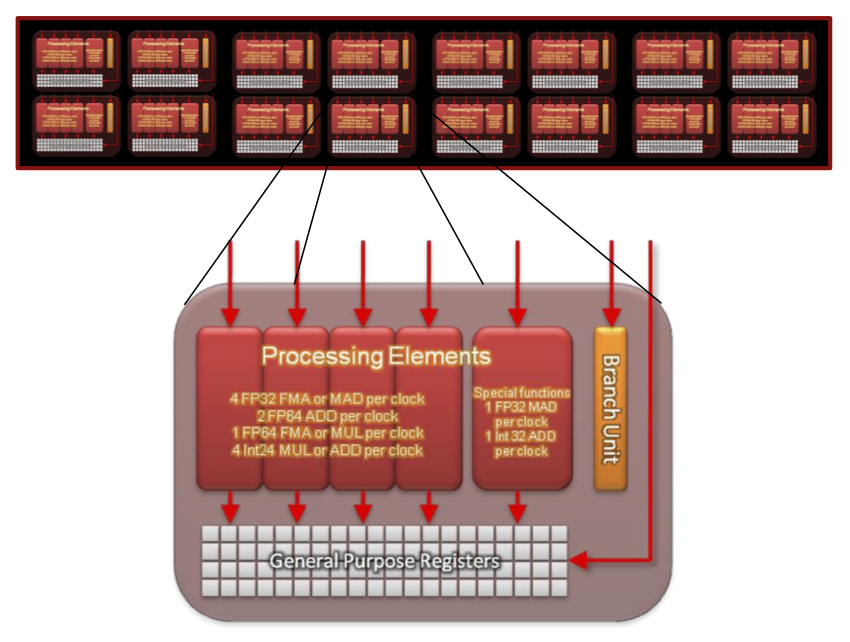
Heterogeneous Programming Tools
There are several common options available for adapting existing code to run on GPUs. There are many libraries available that can be sued with some being drop-in replacements for commonly used libraries. This can be the most accessible method taking advantage of GPUs. Additionally, several commonly used high-level languages provide interfaces to lower level GPGPU languages provide much of the functionality with a reduced learning curve. Finally, there are low level, but now standard and, in one case, standardized, languages that can be used to explicitly program these devices. Thus, there are various levels of access with increasing difficultly.
The primary difficulty in programming and using GPUs for general purpose calculations is data locality. Using libraries can help optimize data locality, but when using lower level languages, understand exactly where your data is and how and when to move it is critical to good performance.
- Libraries
- There are many libraries available that implement commonly used functions on GPGPUs.
- OpenCL
- OpenCL (Open Compute Language) is a C-based programming language designed to be hardware agnostic. As such, it supports a wide variety of heterogeneous platforms.
- CUDA
- CUDA is a very popular C-based programming language to program NVIDIA GPUs. It has many features that make programming GPUs easier than OpenCL, but it is specific to NVIDIA hardware.
- OpenACC and OpenMP
- These are pragma and directive based tools use to decorate code to provide instructions to compiles as to what and how sections of code can be run on an accelerator. OpenACC and OpenMP each began their work independently, but have since begun the work of integrating their standards as they are very similar.
High-Level Languages
There are a handful of high-level languages that allow for GPU-based calculations. Access to the GPU can be through function libraries or directly through lower level languages.
In the following sections a series of calculations are implemented in CPU and GPU variants in several high-level languages.
R
R is a popular statistics programming language with a huge library of additional functions.
Python
Python is a very popular language in scientific and high-performance computing due to its easy-to-learn syntax and its forgiving dynamic type system. There is a immensely rich set of libraries available and a vibrant user community.
- Numba
- Numba is a Python just-in-time compiler that can uses decorators to instruct the interpreter when to compile blocks of code. The compilation can be done for CPUs and GPUs.
- PyCUDA and PyOpenCL
- PyCUDA and PyOpenCL provide API access from Python allowing for direct compilation and execution of kernels written the respective languages.
MATLAB
MATLAB is a popular language and computing environment, particularly in engineering. MATALB provides a libraries and toolboxes that are GPU accelerated and functions for kernel execution. Currently, MATLABs GPGPU implementation is based on CUDA and is therefore restricted to NVIDIA GPUs.
Mathematica
Mathematica is a computation platform that is also very popular. Mathematica provides GPU accelerated libraries and functions for kernel execution. Some libraries and functions are implemented in CUDA and some in OpenCL. Thus, not all functions may be available on non-NVIDIA GPUs.
Libraries
Libraries can provide drop-in replacement functions in some situations, this is particularly true of math functions.
Advantages
- Library is developed by performance expert
- Can be used by average developer
- Accelerates development process
- Often programmer does not even need to think about parallelism
- Parallelism is embedded in the library itself
Disadvantages
- Difficult to customize to specific contexts
- Complex and difficult to understand
Many Libraries Available
- Open source
- Linear algebra library MAGMA (BSD)
- Array-based function library ArrayFire (BSD)
- Parallel algorithms and data structure library Thrust (Apache License 2.0)
- High-throughput sequence analysis library NVBIO (BSD)
- High Performance Linear Algebra in R HiPLAR (GPL2)
- Computer vision OpenCV (BSD)
- Sparse iterative methods PARALUTION (GPL3 & commercial)
- Sparse matrix algorithms SuiteSparse (LGPL2 and GPL2)
- Free for non-commerical
- Solver suite AmgX
- Deep learning cuDNN
- Fast Fourier transform (FFT) library cuFFT
- Image, video, and signal processing library NPP
- Linear algebra library CULA
- Dense and sparse direct solver library cuSOLVER
- Sparse matrix library cuSPARSE
- Basic Linear Algebra Subroutines (BLAS) library cuBLAS
- Random number generation library cuRAND
- Standard mathematical function library CUDA Math Library
OpenACC
OpenACC is a set of high-level directives can be added to C/C++ or Fortran programs. The standard marks loops or blocks of statements that can be offloaded to an attached accelerator. The standard is similar to OpenMP and is portable across various operating systems, host-types, and accelerator-types. The standard was accounts by Nvidia, Cray, PGI, and CAPS at Supercomputing 2011 and has since begun being integrated in to the OpenMP standard.
#pragma acc parallel [clause[,]…]
block of code or loop
With OpenACC the execution model is similar to that of OpenMP and the fork-join parallelization strategy is employed.

A simple example demonstrating the use of OpenACC statements is show in the implementation of the commonly used SAXPY function. SAXPY stands for “Single-Precision A·X Plus Y”. It is a function in the standard Basic Linear Algebra Subroutines (BLAS)library. SAXPY is a combination of scalar multiplication and vector addition, and it’s very simple: it takes as input two vectors of 32-bit floats X and Y with N elements each, and a scalar value A. It multiplies each element X[i] by A and adds the result to Y[i]. A simple C implementation looks like this.
#include <stdlib.h>
void saxpy(int n, float a, float *x, float *restrict y) {
#pragma acc parallel loop
for (int i = 0; i < n; ++i)
y[i] = a * x[i] + y[i];
}
int main(int argc, char **argv) {
int N = 1<<20; // 1 million floats
if (argc > 1) N = atoi(argv[1]);
float *x = (float*)malloc(N * sizeof(float));
float *y = (float*)malloc(N * sizeof(float));
for (int i = 0; i < N; ++i) {
x[i] = 2.0f;
y[i] = 1.0f;
}
saxpy(N, 3.0f, x, y);
return 0;
}
The program is compiled using very standard commands.
pgcc -acc saxpy_openacc.c -o saxpy_openacc
Advantages
- Ability to add GPU code to existing program with very low effort, similar to OpenMP vs. Pthreads
- Compiler deals with complexity of index expressions, data movement, synchronization
- Has the potential to be portable and non-proprietary if adopted by other vendors
- Real gains are being achieved on real applications
Disadvantages
- Performance may suffer, possibly a lot
- Cannot express everything that can be expressed in CUDA
- Still not widely adopted by the community, but it is new so this may change
OpenCL
OpenCL is an open source standard specification for developing heterogeneous parallel applications, i.e. parallel codes that use a mix of different functional units. The goal of the standard is to unify how parallelism is expressed, how to offload computation to accelerators like GPUs, and how to port code from one platform to another. The initial version is based on ISO C99.
- Data-parallel programming interface to GPU
- Data to be operated on is discretized into independent partition of memory
- Each thread performs roughly same computation to different partition of data
- When appropriate, easy to express and very efficient parallelization
- Programmer expresses:
- Thread programs to be launched on GPU, and how to launch
- Data placement and movement between host and GPU
- Synchronization, memory management, testing, etc.
Advantages
- Not proprietary
- Portable and ot hardware specific
Disadvantages
- Not necessarily performance portable
- Low level in terms of programmer abstractions
OpenCL Workflow
The host program is the code that runs on the host to setup the environment for the OpenCL program and create and manage kernels. This is done in five steps in a basic program.
- Define the platform (devices, context, and queues)
- Create and build the kernel
- Setup memory objects
- Define the kernel
- Submit commands: transfer memory objects and execute kernels
Example
//
// saxpy.c
//
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <math.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <OpenCL/opencl.h>
// Use a static data size for simplicity
#define DATA_SIZE (1024)
#define SEPARATOR ("----------------------------------------------------------------------\n")
// Simple kernel for computing the saxpy operation with real single precision
// vectors
const char *KernelSource = "\n" \
"__kernel void saxpy( \n" \
" const unsigned int n, \n" \
" const float a, \n" \
" __global float* x, \n" \
" __global float* y) \n" \
"{ \n" \
" int i = get_global_id(0); \n" \
" if(i < n) \n" \
" y[i] = a * x[i] + y[i]; \n" \
"} \n" \
"\n";
// Prototype for device reporting function
cl_int report_and_mark_devices(cl_device_id *, cl_uint, int *, int *, int *);
int main(int argc, char** argv)
{
cl_int err; // error code returned from api calls
float x[DATA_SIZE]; // original data vector x given to device
float y[DATA_SIZE]; // original data vector y given to device
float a;
float results[DATA_SIZE]; // results returned from device
unsigned int correct; // number of correct results returned
cl_device_id device_id; // compute device id
int gpu = 1;
if (argc == 1) {
printf("%s -trying to use CL_DEVICE_GPU\n",argv[0]);
} else if (argc == 2) {
gpu = atoi(argv[1]);
if (gpu != 0 && gpu != 1) {
printf("Usage: %s 0 -use CL_DEVICE_CPU\n",argv[0]);
printf("Usage: %s 1 -use CL_DEVICE_GPU or CL_DEVICE_ACCELERATOR\n",argv[0]);
return EXIT_FAILURE;
}
printf("%s -trying to use %s\n",argv[0], gpu ? "CL_DEVICE_GPU or CL_DEVICE_ACCELERATOR" :
"CL_DEVICE_CPU");
}
// Fill our data set with random float values
int i = 0;
a = 2.0;
unsigned int count = DATA_SIZE;
for(i = 0; i < count; i++) {
x[i] = rand() / (float)RAND_MAX;
y[i] = rand() / (float)RAND_MAX;
}
// Trying to identify one platform:
cl_platform_id platform;
cl_uint num_platforms;
err = clGetPlatformIDs(1,&platform,&num_platforms);
if (err != CL_SUCCESS) {
printf("Error: Failed to get a platform id!\n");
return EXIT_FAILURE;
}
// Found one platform. Query specific information about the found platform using the function
//
// Trying to query platform specific information...
size_t returned_size = 0;
cl_char platform_name[1024] = {0}, platform_prof[1024] = {0}, platform_vers[1024] = {0}, platform_exts[1024] = {0};
err = clGetPlatformInfo(platform, CL_PLATFORM_NAME, sizeof(platform_name), platform_name, &returned_size);
err |= clGetPlatformInfo(platform, CL_PLATFORM_VERSION, sizeof(platform_vers), platform_vers, &returned_size);
err |= clGetPlatformInfo(platform, CL_PLATFORM_PROFILE, sizeof(platform_prof), platform_prof, &returned_size);
err |= clGetPlatformInfo(platform, CL_PLATFORM_EXTENSIONS, sizeof(platform_exts), platform_exts, &returned_size);
if (err != CL_SUCCESS) {
printf("Error: Failed to get platform infor!\n");
return EXIT_FAILURE;
}
printf("\nPlatform information\n");
printf(SEPARATOR);
printf("Platform name: %s\n", (char *)platform_name);
printf("Platform version: %s\n", (char *)platform_vers);
printf("Platform profile: %s\n", (char *)platform_prof);
printf("Platform extensions: %s\n", ((char)platform_exts[0] != '\0') ? (char *)platform_exts : "NONE");
// Getting a list of available compute devices on our platform by function
//
// Get all available devices (up to 4)
cl_uint num_devices;
cl_device_id devices[4];
err = clGetDeviceIDs(platform, CL_DEVICE_TYPE_ALL, 4, devices, &num_devices);
if (err != CL_SUCCESS) {
printf("Failed to collect device list on this platform!\n");
return EXIT_FAILURE;
}
printf(SEPARATOR);
printf("\nFound %d compute devices!:\n",num_devices);
// Collect and report device information, return indices of devices of type CL_DEVICE_TYPE_CPU,
// CL_DEVICE_TYPE_GPU and CL_DEVICE_TYPE_ACCELERATOR in array devices
int a_cpu=-1, a_gpu=-1, an_accelerator=-1;
err = report_and_mark_devices(devices,num_devices,&a_cpu,&a_gpu,&an_accelerator);
if (err != CL_SUCCESS) {
printf("Failed to report information about the devices on this platform!\n");
return EXIT_FAILURE;
}
// Checking for availability of the required device
if (gpu == 0) { // No accelerator or gpu, just cpu
if (a_cpu == -1) {
printf("No cpus available, weird...\n");
return EXIT_FAILURE;
}
device_id = devices[a_cpu];
printf("There is a cpu, using it\n");
}
else { // Trying to find a gpu, or if that fails, an accelerator
if (a_gpu != -1) { // There is a gpu in our platform
device_id = devices[a_gpu];
printf("Found a gpu, using it\n");
} else if (an_accelerator != -1) {
device_id = devices[an_accelerator];
printf("No gpu but found an accelerator, using it\n");
} else {
printf("No cpu, no gpu, nor an accelerator... where am I running???\n");
return EXIT_FAILURE;
}
}
// We have a compute device of required type! Next, create a compute context on it.
printf("\n");
printf(SEPARATOR);
printf("\nCreating a compute context for the required device\n");
cl_context context; // compute context
context = clCreateContext(NULL, 1, &device_id, NULL, NULL, &err);
if (!context) {
printf("Error: Failed to create a compute context!\n");
return EXIT_FAILURE;
}
// Create a command-queue on a specific device. The context must be a valid OpenCL context.
printf("\n");
printf(SEPARATOR);
printf("\nCreating a command queue\n");
cl_command_queue commands;
commands = clCreateCommandQueue(context, device_id, 0, &err);
if (!commands) {
printf("Error: Failed to create a command queue!\n");
return EXIT_FAILURE;
}
// Create the compute program object for our context and load the source code from the source buffer
printf("\n");
printf(SEPARATOR);
printf("\nCreating the compute program from source\n");
printf("%s\n", KernelSource);
cl_program program; // compute program
program = clCreateProgramWithSource(context, 1, (const char **) &KernelSource, NULL, &err);
if (!program) {
printf("Error: Failed to create compute program!\n");
return EXIT_FAILURE;
}
// Build the program executable
printf(SEPARATOR);
printf("\nCompiling the program executable\n");
err = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
if (err != CL_SUCCESS) {
size_t len;
char buffer[2048];
printf("Error: Failed to build program executable!\n");
// See page 98...
clGetProgramBuildInfo(program, device_id, CL_PROGRAM_BUILD_LOG, sizeof(buffer), buffer, &len);
printf("%s\n", buffer);
exit(1);
}
// Create the compute kernel object in the program we wish to run
printf("\n");
printf(SEPARATOR);
printf("\nCreating the compute kernel from program executable\n");
cl_kernel kernel; // compute kernel
kernel = clCreateKernel(program, "saxpy", &err);
if (!kernel || err != CL_SUCCESS) {
printf("Error: Failed to create compute kernel!\n");
exit(1);
}
// Create buffer objects for the input and input/output arrays in device memory for our calculation
printf("\n");
printf(SEPARATOR);
printf("\nCreating the input and input/output arrays in device memory\n");
cl_mem dx; // device memory used for the input array x
cl_mem dy; // device memory used for the input/output array y
dx = clCreateBuffer(context, CL_MEM_READ_ONLY, sizeof(float) * count, NULL, NULL);
dy = clCreateBuffer(context, CL_MEM_READ_WRITE, sizeof(float) * count, NULL, NULL);
if (!dx || !dy) {
printf("Error: Failed to allocate device memory!\n");
exit(1);
}
// Write our data set into the input buffer object in device memory
printf("\n");
printf(SEPARATOR);
printf("\nWriting the data into the input and input/output arrays in device memory\n");
err = clEnqueueWriteBuffer(commands, dx, CL_TRUE, 0, sizeof(float) * count, x, 0, NULL, NULL);
err |= clEnqueueWriteBuffer(commands, dy, CL_TRUE, 0, sizeof(float) * count, y, 0, NULL, NULL);
if (err != CL_SUCCESS) {
printf("Error: Failed to write to source array!\n");
exit(1);
}
// Setting the arguments to our compute kernel in order to execute it.
printf("\n");
printf(SEPARATOR);
printf("\nSetting the kernel arguments\n");
err = 0;
err = clSetKernelArg(kernel, 0, sizeof(unsigned int), &count);
err |= clSetKernelArg(kernel, 1, sizeof(float), &a);
err |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &dx);
err |= clSetKernelArg(kernel, 3, sizeof(cl_mem), &dy);
if (err != CL_SUCCESS) {
printf("Error: Failed to set kernel arguments! %d\n", err);
exit(1);
}
// Get the maximum kernel work group size for executing the kernel on the device
size_t local; // local domain size for our calculation
err = clGetKernelWorkGroupInfo(kernel, device_id, CL_KERNEL_WORK_GROUP_SIZE, sizeof(local), &local, NULL);
if (err != CL_SUCCESS) {
printf("Error: Failed to retrieve kernel work group info! %d\n", err);
exit(1);
}
// Execute the kernel over the entire range of our logically 1d configuration
// using the maximum kernel work group size
size_t global; // global domain size for our calculation
global = count;
printf("\n");
printf(SEPARATOR);
printf("\nExecuting the kernel over 1d range %d.\n", (int)global);
printf("Maximum work group size for this kernel is %d on this device\n", (int)local);
err = clEnqueueNDRangeKernel(commands, kernel, 1, NULL, &global, &local, 0, NULL, NULL);
if (err) {
printf("Error: Failed to execute kernel!\n");
return EXIT_FAILURE;
}
// Wait for the command commands to get serviced before reading back results
clFinish(commands);
// Read back the results from the device to verify the output. In order to fully mimic
// the saxpy operation, the result should be read into the array y, we read it to array results
// in order to verify the computations.
printf("\n");
printf(SEPARATOR);
printf("\nReading back the results from the device\n");
err = clEnqueueReadBuffer( commands, dy, CL_TRUE, 0, sizeof(float) * count, results, 0, NULL, NULL );
if (err != CL_SUCCESS) {
printf("Error: Failed to read output array! %d\n", err);
exit(1);
}
// Validate our results
correct = 0;
for(i = 0; i < count; i++) {
if(results[i] == a*x[i] + y[i])
correct++;
}
// Print a brief summary detailing the results
printf("\n");
printf(SEPARATOR);
printf("\nComputed '%d/%d' correct values!\n", correct, count);
// Shutdown and cleanup
clReleaseMemObject(dx);
clReleaseMemObject(dy);
clReleaseProgram(program);
clReleaseKernel(kernel);
clReleaseCommandQueue(commands);
clReleaseContext(context);
return 0;
}
cl_int report_and_mark_devices(cl_device_id *devices, cl_uint num_devices, int *a_cpu, int *a_gpu, int *an_accelerator)
{
int i, type_name_index = 0;
cl_int err = 0;
size_t returned_size;
size_t max_workgroup_size = 0;
cl_uint max_compute_units = 0, vec_width_char = 0, vec_width_short = 0;
cl_uint vec_width_int = 0, vec_width_long = 0, vec_width_float = 0, vec_width_double = 0;
char vendor_name[1024] = {0}, device_name[1024] = {0}, device_version[1024] = {0};
cl_ulong global_mem_size;
cl_device_type device_type;
char type_names[3][27]={"CL_DEVICE_TYPE_CPU " , "CL_DEVICE_TYPE_GPU " , "CL_DEVICE_TYPE_ACCELERATOR"};
for (i=0;i<num_devices;i++) {
err = clGetDeviceInfo(devices[i], CL_DEVICE_TYPE, sizeof(device_type), &device_type, &returned_size);
err|= clGetDeviceInfo(devices[i], CL_DEVICE_VENDOR, sizeof(vendor_name), vendor_name, &returned_size);
err|= clGetDeviceInfo(devices[i], CL_DEVICE_NAME, sizeof(device_name), device_name, &returned_size);
err|= clGetDeviceInfo(devices[i], CL_DEVICE_VERSION, sizeof(device_version), device_version, &returned_size);
err|= clGetDeviceInfo(devices[i], CL_DEVICE_MAX_WORK_GROUP_SIZE, sizeof(size_t), &max_workgroup_size, &returned_size);
err|= clGetDeviceInfo(devices[i], CL_DEVICE_MAX_COMPUTE_UNITS, sizeof(cl_uint), &max_compute_units, &returned_size);
err|= clGetDeviceInfo(devices[i], CL_DEVICE_GLOBAL_MEM_SIZE, sizeof(cl_ulong), &global_mem_size, &returned_size);
err|= clGetDeviceInfo(devices[i], CL_DEVICE_PREFERRED_VECTOR_WIDTH_CHAR, sizeof(cl_uint), &vec_width_char, &returned_size);
err|= clGetDeviceInfo(devices[i], CL_DEVICE_PREFERRED_VECTOR_WIDTH_SHORT, sizeof(cl_uint), &vec_width_short, &returned_size);
err|= clGetDeviceInfo(devices[i], CL_DEVICE_PREFERRED_VECTOR_WIDTH_INT, sizeof(cl_uint), &vec_width_int, &returned_size);
err|= clGetDeviceInfo(devices[i], CL_DEVICE_PREFERRED_VECTOR_WIDTH_LONG, sizeof(cl_uint), &vec_width_long, &returned_size);
err|= clGetDeviceInfo(devices[i], CL_DEVICE_PREFERRED_VECTOR_WIDTH_FLOAT, sizeof(cl_uint), &vec_width_float, &returned_size);
err|= clGetDeviceInfo(devices[i], CL_DEVICE_PREFERRED_VECTOR_WIDTH_DOUBLE, sizeof(cl_uint), &vec_width_double, &returned_size);
if (err != CL_SUCCESS) {
printf("Error: Failed to retrieve device info!\n");
return EXIT_FAILURE;
}
if (device_type == CL_DEVICE_TYPE_CPU) {
*a_cpu = i;
type_name_index = 0;
}
if (device_type == CL_DEVICE_TYPE_GPU) {
*a_gpu = i;
type_name_index = 1;
}
if (device_type == CL_DEVICE_TYPE_ACCELERATOR) {
*an_accelerator = i;
type_name_index = 2;
}
printf("\nDevice information:\n");
printf(SEPARATOR);
printf("Type: %s\n", type_names[type_name_index]);
printf("Vendor: %s\n", vendor_name);
printf("Device: %s\n", device_name);
printf("Version: %s\n", device_version);
printf("Max workgroup size: %d\n", (int)max_workgroup_size);
printf("Max compute units: %d\n", (int)max_compute_units);
printf("Global mem size: %ld\n", (long)global_mem_size);
printf(SEPARATOR);
printf("\nPreferred vector widths by type:\n");
printf(SEPARATOR);
printf("Vector char: %d\n", (int)vec_width_char);
printf("Vector short: %d\n", (int)vec_width_short);
printf("Vector int: %d\n", (int)vec_width_int);
printf("Vector long: %d\n", (int)vec_width_long);
printf("Vector float: %d\n", (int)vec_width_float);
printf("Vector dble: %d\n", (int)vec_width_double);
printf(SEPARATOR);
printf("\n");
}
return err;
}
References
This session has been adapted form the following references: